Carnet de lecture pour L’Hypothèse K. – Aurélien Barrau
Un mot : Fataliste.
le second livre d’Aurélien Barrau dédié à la catastrophe écologique après « Le Plus Grand Défi de l’histoire de l’humanité ». Si ce dernier était factuel, direct et grave, « L’hypothèse K. » prend à bras le corps la responsabilité de la science dans cette catastrophe inéluctable, avec toute la crédibilité imposée par l’éminence scientifique de son auteur.
Le constat d’Aurélien Barrau est dur : la science a une grande part de responsabilité dans ce qui arrive, et malheureusement, on ne peut (on ne doit) pas attendre d’elle qu’elle apporte des solutions.
Un portrait sombre de l’utilisation faite aujourd’hui des « avancées » de la science. La vacuité et l’inutilité de l’IA générative en est un excellent exemple :
Un compte rendu de consultation ou un chapitre de thèse écrit par ChatGPT, à partir de mots-clés livrés par le médecin ou la chercheuse, violent le pacte fondamental de l’idiome. La douce et anxieuse exégèse d’un texte – même le plus futile ou le plus trivial – repose sur la promesse non dite de ce que chaque lettre, chaque mot, chaque forme grammaticale doit pouvoir, en principe, livrer quelque chose de l’auteur ou de la locutrice et de leurs propres arborescences symboliques. Il y a toujours palimpseste. Lire un texte écrit par une intelligence artificielle revient à faire l’amour avec une poupée gonflable. Tout y est… sauf l’amour. Plus qu’insipides, ces perspectives déliquescentes dévoilent nos dépendances nécro-techno-philes. Le dénoncer relève de la plus extrême urgence mais la tâche ne saurait échoir ni à la science ni à ses mandataires ou à ses ambassadrices.
Étant donné que le fonctionnement de ChatGPT est, par ailleurs, fondé sur la complétion probabiliste des phrases à partir des motifs appris dans les textes intégrés ou ingérés – sans que le concept de vérité soit jamais invité dans le processus -, c’est également la référence au réel qui est perdue. Il s’agit donc d’une double déréférentialisation : perte du lien avec le monde et perte du lien avec l’écrivain ou l’oratrice. Double trahison des deux piliers de la langue, des deux promesses dialectales élémentaires.
L’auteur n’hésite pas à comparer la fuite en avant technophile à un cancer, un carcinome, « l’hypothèse K. » et s’avoue pessimiste, fataliste, voire vaincu, face à ce constat.
D’abord, il pourrait être question, pour les scientifiques, de trahir. Non pas, bien sûr, de trahir les paroles données ou les amours promises. Moins encore l’honnêteté à laquelle ils et elles ont fait allégeance. Rien ne serait plus triste et plus vil. Il s’agirait plutôt de trahir les pratiques héritées et les suivismes implicites. C’est difficile de trahir: on quitte bien plus que sa zone de confort, on abandonne son monde de domination. On perd ses affidés d’antan en demeurant suspect aux yeux de ses alliés à venir.
Un texte superbe, pour un constat mélancolique, déprimant, mais certainement incontestable.
Carnet de lecture pour Terminus – Tom Sweterlitsch
Un mot : Confus.
Un mélange brouillon entre un polar et un roman de SF, qui ne brille ni dans l’un ni dans l’autre.
L’enquête policière n’est pas intéressante. Violences gratuites, surenchère de gore. On comprend mal l’empathie, l’intérêt, voire l’obstination de l’enquêtrice.
Des passages sentimentaux qui ne servent ni l’histoire, ni la construction du personnage.
La partie SF présente un intérêt : le voyage dans le temps est bien construit, avec les lignes temporelles qui ne peuvent que se projeter dans le futur, et sans conséquence sur le passé. Mais cette « facilité » pousse l’auteur à en abuser : on sent qu’il tente néanmoins de générer des paradoxes temporels pour perdre le lecteur, avec des personnages qui se dédoublent, changent de personnalité. Le twist facile.
Termes scientifiques employés à tort et à travers pour faire pompeux, et qui nuisent finalement à la crédibilité (mousse quantique, ligne de casimir, etc.)
Des choix (erreurs ?) de style difficile à comprendre : pourquoi le passage à la première personne en plein milieu du livre, puis un retour à la troisième ensuite ?
Des références évidentes à Twin Peaks : le parc régional Blackwater avec ses lodges, ses sapins, ses meurtres, et surtout son lieu de passage spatio-temporel façon black lodge, mais bon… N’est pas David Lynch qui veut.
Résolution des paradoxes temporels à la « armée des 12 singes », mais de manière peu originale et attendue dans le twist final.
Fin un peu mièvre.
Étonnamment, je lui ai mis 4/10 mais j’ai eu envie d’aller au bout, et j’ai trouvé qu’il y avait de bonnes idées… Mais c’est un brouillon mal exploité, un peu gâché.
Plus un journal qu’un roman. Style très cru, factuel.
L’expérience brute de la pauvreté et de la déchéance. Toujours plus bas, quelle que soit les choix, quel que soit le lieu, à Paris ou Londres.
Des détails sordides de la misère mais terriblement réalistes. Le quotidien des clochards, qui ne doit pas être si loin de la réalité d’aujourd’hui.
Triste fatalité de ceux qui ne pourront jamais s’en sortir, même avec la meilleure volonté. L’acceptation de la détresse, de la dèche. Comment s’accommoder, s’habituer aux conditions les plus crasses. Comment l’humain cherche et trouve toujours un fragment d’espoir et de réconfort, aussi dérisoire soit-il. La solidarité qui peut naitre de cette misère, mais qui contribue à l’acceptation de la condition.
L’exploitation du patronat pour grapiller toujours plus sur le dos des employés exploités, ceux qui n’ont pas d’autre choix. L’arnaque et les petites magouilles à tous les niveaux. On oublie qu’on est exploités dès lors qu’on peut soi-même en exploiter d’autres.
L’OWASP Top 10 est probablement le rapport le plus connu dans le domaine de la sécurité des applications web. Il répertorie les 10 risques et vulnérabilités les plus critiques, qu’il convient d’adresser en priorité. Et pourtant, il n’est pas toujours facile à comprendre.
La semaine dernière, je donnais un cours de cybersécurité à mes étudiants, et je devais leur expliquer les 10 vulnérabilités OWASP. Or, nous n’avions plus que 10 minutes ! Il a donc fallu synthétiser à l’extrême, sans perdre les concepts structurants de chacun des cas. Et puis, j’ai réalisé que l’on me demandait assez régulièrement le même exercice. La documentation OWASP est très complète, mais je sais que vous n’avez pas le temps de tout lire. Alors, je vous ai préparé une explication « ELI5 » (Explique moi comme si j’avais 5 ans) de chacune de ces vulnérabilités, avec un petit conseil à appliquer pour chacune.
Pour tester et identifier les vulnérabilités de sécurité dans les applications, on distingue trois grandes familles de solutions dédiées : les outils de tests dynamiques de la sécurité des applications (DAST : Dynamic Application Security Testing), les outils de tests statiques de sécurité des applications (SAST : Static Application Security Testing) et enfin les outils d’analyse de la composition des logiciels (SCA : Software Composition Analysis)
Les DAST pour détecter les vulnérabilités des applications en temps réel
Les DAST sont des outils qui permettent d’analyser une application en cours d’exécution en simulant des attaques via ses URLs, ses APIs et ses points de terminaison dans une architecture de système distribué (les endpoints[1]).
En recherchant les faiblesses dans les protocoles de communication, l’architecture et les configurations d’exécution, les DAST peuvent déterminer si l’application est vulnérable.
Cependant, les vulnérabilités détectées par les DAST peuvent être coûteuses à corriger car elles nécessitent souvent une rétro-ingénierie approfondie.
Bien que les DAST revêtent toutes une importance cruciale dans les tests de sécurité, elles ne peuvent garantir individuellement une protection intégrale des applications. Par conséquent, pour une sécurité maximale, elles peuvent être associé avec un outil de test statique de sécurité des applications (SAST).
SAST : la sécurité du code en temps réel
Les scanners SAST sont des outils qui permettent de détecter en temps réel les pratiques de codage à risque dans le code source d’une application. Ces scanners utilisent une analyse statique pour identifier les vulnérabilités et les faiblesses en matière de sécurité du code source.
Contrairement aux scanners dynamiques qui analysent l’application en cours d’exécution, les SAST inspectent le code source de l’application pour signaler les lignes de code suspectes aux développeurs, leur permettant ainsi de prendre des décisions éclairées avant le déploiement des applications.
Cependant, il est important de noter que les scanners peuvent parfois signaler des vulnérabilités qui ne sont pas pertinentes. C’est ce qu’on appelle un « faux positif ». Cette situation peut être frustrante pour les développeurs. Elle peut en effet entraîner une perte de temps et d’efforts considérable pour évaluer ces alertes non pertinentes. C’est compréhensible, car cela peut être comparé à être accusé à tort d’une erreur que l’on n’a pas commise.
SCA : la solution de détection des vulnérabilités des librairies externes
Les solutions d’analyse de composition de logiciels (SCA) identifient les librairies, les composants tiers et open-source couramment utilisés dans le code d’une application et les comparer à des listes de vulnérabilités connues.
Même si ces librairies ont été testées, elles peuvent toujours présenter des failles exploitables par des attaquants. Pour corriger une vulnérabilité détectée, l’équipe de développement doit généralement mettre à jour la bibliothèque défectueuse.
Si le support d’une bibliothèque a été abandonné, des modifications plus importantes peuvent s’avérer nécessaires. Au pire, ils peuvent désactiver temporairement certaines fonctionnalités.
AST : Les critères d’évaluation à connaître pour sauter le pas
Les logiciels SAST et SCA ne se valent pas tous et chacun possède ses forces et faiblesses. Il est important de faire une évaluation approfondie de chaque option disponible sur le marché : ceux du coût, de la compatibilité des langages, de la facilité d’intégration, du rapport de sécurité et de la facilité d’utilisation, de la personnalisation et la précision.
Coût
Outre le prix de la solution, il est important de prendre en compte le modèle de tarification, la taille de votre base de code, le nombre d’utilisateurs et le niveau d’assistance fourni.
Compatibilité des langages
Ensuite, vous devez prendre en compte la capacité de l’outil à prendre en charge différents langages et frameworks pour détecter les vulnérabilités.
Facilité d’intégration
L’outil doit s’intégrer facilement dans les outils de développement et les pipelines CI/CD pour faciliter l’analyse de sécurité et optimiser les flux de travail.
Rapport de sécurité
Les rapports de sécurité sont également essentiels pour communiquer les résultats des analyses de sécurité. Certains outils fournissent des rapports détaillés avec des conseils de remédiation exploitables, tandis que d’autres ne fournissent que des résumés de haut niveau.
Expérience utilisateur
Bien entendu, la facilité d’utilisation, l’ergonomie de l’interface utilisateur et la rapidité de scan et d’exécution sont des facteurs clés qui influence le choix des utilisateurs.
La personnalisation
Lorsqu’il s’agit de choisir un outil de sécurité pour votre code, la personnalisation des règles de sécurité est un critère de poids à prendre en compte. Les outils qui proposent des options pour modifier ou ajouter des règles personnalisées, ainsi que définir des seuils personnalisés pour les niveaux de criticité, sont essentiels pour garantir que votre application est correctement sécurisée selon vos besoins spécifiques.
La précision
Sa précision pour identifier les vraies vulnérabilités et éviter les faux positifs (une vulnérabilité identifiée qui n’existe pas) ou les faux négatifs (une vulnérabilité non identifiée qui existe). Les faux positifs font perdre du temps aux équipes de développement, tandis que les faux négatifs peuvent rendre votre application vulnérable.
De toutes ces critères de choix, nous pensons que les deux derniers, la personnalisation et la précision, sont vraiment essentiels pour répondre aux vagues de vulnérabilités et pour choisir ce qui convient de corriger ou pas.
Posons le décor. Le marché mondial DevSecOps a été évaluée à 2,79 milliards de dollars en 2020 et devrait croître de 24% par an de 2021 à 2028. C’est une inéluctable réalité : les applications doivent être hautement sécurisées, et la demande d’automatisation dans ce domaine a explosé.
De plus, la pression sur les équipes informatiques est croissante. Elles subissent les changements structurels des systèmes d’information qui découlent des régulations et des enjeux d’innovation.
Aussi, pour pouvoir tenir les engagements en termes de résilience, disponibilité et sécurité des applications, ces équipes doivent hiérarchiser leurs activités et optimiser leurs ressources limitées.
Il ne faut pas être expert pour comprendre qu’il ne sera jamais possible de corriger toutes les vulnérabilités des applications. Dès lors, il convient surtout de mettre l’accent sur les failles les plus critiques pour l’entreprise. Pour y parvenir, l’approche « secure by design », consistant à intégrer la sécurité dès la conception des systèmes logiciels, est tout indiquée.
Nous le verrons, il existe bien des outils dédiés aux tests de sécurité comme SAST, DAST, et SCA. Cependant, aucun de ces derniers ne peut répondre à tous les besoins de sécurité. Dans ce contexte, la gestion des vulnérabilités fondée sur le risque (Risk Based Vulnerability Management) peut aider les équipes IT à cibler efficacement leurs efforts pour améliorer la sécurité des applications.
Security by Design : 5 principes pour anticiper les enjeux de sécurisation
La sécurité des logiciels est un enjeu majeur pour protéger les données des utilisateurs et minimiser les risques cyber. C’est pourquoi l’industrie du développement logiciel préconise d’intégrer la sécurité dès le début des projets et tout au long de leur cycle de vie. Cette approche de la cybersécurité appelé Security by Design (ou « sécurité par la conception « ) est désormais obligatoire depuis l’adoption du Cyber Resilience Act par Bruxelles en 2022.
En pratique, la Security by Design consiste à adopter des pratiques de sécurité rigoureuses à chaque étape du processus de développement et de déploiement des logiciels. Voici ces 5 principes clés pour garantir la sécurité des logiciels dès leur conception :
Modélisation des menaces
L’une de ces pratiques clés est la « modélisation des menaces » (ou Threat Modeling). Cette action permet d’anticiper les risques et les vulnérabilités latentes dès l’amorce même de la phase de conception.
Minimiser la surface d’attaque
Réduire la surface d’attaque constitue la seconde mesure importante de sécurité pour assurer la sécurité des systèmes informatiques. L’objectif, ici, est de limiter les opportunités pour les attaquants de trouver des failles et d’exploiter des vulnérabilités. On vise ainsi à limiter l’accès aux données et fonctionnalités sensibles.
Principe de moindre privilège (PoLP)
La troisième mesure de sécurité est la mise en place du « principe de moindre privilège » (ou Principle of least privilege). Ce dernier limite les droits d’accès des utilisateurs aux seules ressources nécessaires à l’exécution de leurs tâches.
Tests de validation dédiés à la sécurité
Afin d’améliorer la résilience face aux attaques potentielles, la quatrième mesure, la mise en place de tests de validation dédiés à la sécurité, permet, entre autres, de s’assurer du bon cloisonnement des fonctionnalités, et de l’assainissement des entrées de l’application.
Code sécurisé
Enfin, pour minimiser le risque d’erreurs pouvant introduire des vulnérabilités, il est recommandé d’écrire et de déployer un code sécurisé. Pour cela, il convient d’adopter de bonnes pratiques de développement. Ces réflexes s’acquièrent par des formations aux vulnérabilités les plus communes, référencées par la communauté OWASP.
Pour ce dernier point, les développeurs peuvent également utiliser des outils dédiés tels que les tests de sécurité d’application (AST : Application Security Testing). Ces outils leur permettent d’effectuer des vérifications approfondies du code. Mais ces AST sont loin d’être parfaits. L’expérience montre que ces scans remontent beaucoup (trop ?) de vulnérabilités. Dès lors, même en ne traitant que les plus critiques, il apparaît impossible de toutes les corriger.
Alors que faire si on a trop de vulnérabilités à traiter avec un budget ou un délai limité ? La réponse est le « Risk-based vulnerability management », une méthode qui permet d’évaluer et de réduire les risques liés aux vulnérabilités en tenant compte du contexte et de l’impact potentiel sur l’activité.
Évaluer les vulnérabilités pour mieux les prioriser
Vous avez accepté le postulat selon lequel vous vous avez trop de vulnérabilités – réelles ou pas – et pas assez de temps/budget pour tout corriger. Dès lors, il est nécessaire de les prioriser, mais selon quels critères ? Plusieurs métriques sont à votre disposition :
Le Common Vulnerability Scoring System (CVSS)
Le “Common Vulnerability Scoring System” est un système d’évaluation standardisé de la criticité des vulnérabilités, selon des critères objectifs et mesurables. Le score final est compris entre 0 et 10.
Au-delà de 9, la vulnérabilité est « critique » et il est communément admis qu’une vulnérabilité au-delà de 7 (« majeure / high ») devrait être corrigée dès que possible, voire ne pas aller en production.
Notons par ailleurs, qu’une version 4.0 du CVSS est en cours d’adoption depuis juin 2023.
Le score interne des outils
Les outils de détection des vulnérabilités identifient généralement des vulnérabilités bien référencées par leur identifiant CVE (Common Vulnerabilities and Exposures)[9]. Ainsi, la sévérité affichée est communément acceptée et fondée sur le CVSS que nous avons abordé précédemment.
Mais il arrive que certains outils identifient des vulnérabilités non référencées. Ainsi, les équipes de recherche et développement d’un outil SCA peuvent identifier une vulnérabilité « Zero-day » ; c’est-à-dire qui vient d’être découverte, et pour laquelle aucune mitigation n’est encore disponible.
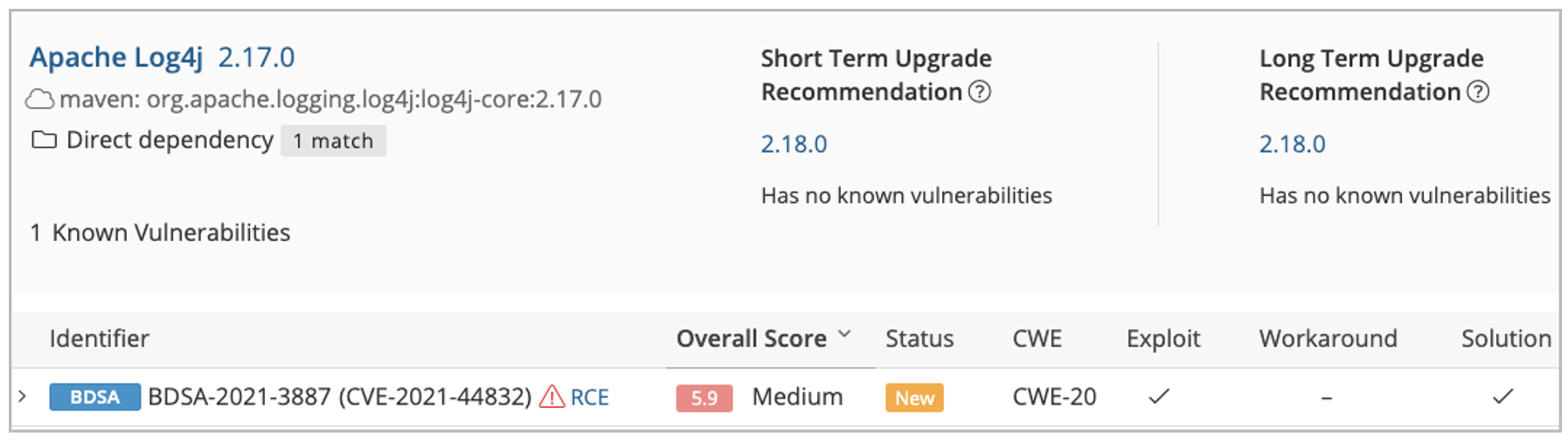
Par exemple, l’outil BlackDuck (Synopsys) attribue des identifiants internes du type « BDSA-YYYY-XXX » ainsi qu’une sévérité interne en attendant une identification standard et reconnue.
La vulnérabilité Log4j identifiée par le SCA BlackDuck, avec son identifiant interne (BDSA) et standard (CVE)
De même, les outils SAST repèrent des vulnérabilités spécifiques au code, propre à l’environnement du projet. Par conséquent, ils ne peuvent hériter d’un identifiant ni même d’un score standard. Les outils utilisent donc leurs propres critères internes.
Par exemple, l’outil Fortify (Micro Focus) propose une notation sur 100, fondée sur la facilité de reproduction, les dommages possibles en cas d’exploitation, la facilité de localisation/découverte, etc.
Ces critères sont empiriques et peuvent parfois manquer de contexte. Il convient de les revoir avec les équipes de développement qui possèdent la connaissance de l’architecture logicielle.
Ces évaluations de vulnérabilités sont reconnues et éprouvées. Cependant, elles ne résoudront probablement pas vos enjeux de priorisation. En effet, trier les vulnérabilités ne diminuera pas leur volume. Il convient alors d’envisager une approche plus pragmatique : le « Risk Based Vulnerability Management ».
Risk Based Management : quel risque concret représente cette vulnérabilité ?
Outre la sévérité affichée d’une vulnérabilité, on peut s’interroger sur son exploitabilité. Dans les faits, est-elle actuellement et activement exploitée par des attaquants ou bien tombée dans l’oubli ?
La note EPSS
Le « EPSS », ou Exploit Prediction Scoring System[11], représente la probabilité qu’une vulnérabilité soit exploitée en ce moment. Cette note s’appuie entre autres sur l’existence d’un exploit dans la nature, et son éventuelle qualification de « zero day ».
Le rapport de PenTest
Un audit de sécurité externe peut être un outil d’aide à la priorisation. Pour cela, il nécessite une analyse affinée et pondérée par un auditeur externe. Ce dernier permettra de contextualiser la criticité de la vulnérabilité en fonction de la facilité d’exploitation, mais aussi de l’expertise requise à sa remédiation.
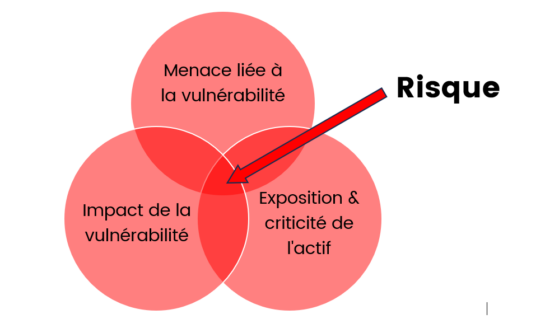
Mais la complexité et l’unicité des systèmes d’informations font qu’une même vulnérabilité n’aura pas forcément la même exploitabilité ni le même impact d’un environnement à l’autre. Ainsi, le risque intrinsèque à la vulnérabilité doit donc être pondéré par des critères spécifiques :
La criticité de l’actif cible
Les enjeux ne seront pas les mêmes selon que l’application vulnérable est critique pour des utilisateurs internes ou externes. De même, la criticité dépendra du volume de données traitées et du nombre d’utilisateurs. Dès lors, il conviendra de définir des engagements suffisants en termes de disponibilité et de reprise d’activité, mais aussi le délai maximum acceptable d’indisponibilité en cas d’attaque.
L’exposition de l’actif cible
Les dispositions à mettre en œuvre vont varier considérablement selon que l’application est exposée sur internet ou uniquement dans un réseau local d’entreprise. De même, son hébergement sur site nécessitera plus de moyens de redondance et de reprise que si elle est hébergée dans le cloud.
L’impact en cas d’attaque
Si la vulnérabilité est exploitée, les conséquences peuvent varier selon le risque propre au business de l’entreprise. Concrètement, il s’agit d’évaluer l’impact financier d’une exploitation de la vulnérabilité : perte de clientèle, amendes. Mais aussi l’impact non-financier : réputation, vol de données business et propriété intellectuelle.
Pour ne plus être submergé par les vulnérabilités : anticiper, évaluer, prioriser
Vous l’aurez compris, il est nécessaire de suivre des principes fondamentaux si l’on veut éviter de crouler sous les vulnérabilités.
Les bonnes pratiques de Security by Design représentent une base fondamentale qu’il faut structurer en amont et au plus tôt des projets.
De plus, il faut s’équiper d’outils d’analyse de code SAST et SCA. Toutefois, nous avons vu que ces outils, bien que nécessaires, ne sont probablement pas suffisants pour évaluer les vulnérabilités des applications. Car en réalité, le nombre de vulnérabilités reste souvent trop important pour pouvoir tout adresser et encore moins tout corriger.
Ainsi, Il est recommandé d’inclure une évaluation du risque relatif à chaque vulnérabilité afin de mesurer sa diffusion et son exploitabilité. En pratique, chaque risque doit être pondéré au regard des actifs de l’organisation, et des impacts éventuels sur le business.
Finalement, vous pourrez ainsi prioriser les efforts des équipes en fonction du risque réel. Vous permettrez alors aux équipes IT de se concentrer sur la véritable valeur ajoutée des fonctionnalités de leurs applications, tout en livrant des produits plus sécurisés.
A suivre : « DAST, SAST et SCA : les outils dédiés aux tests de sécurité d’applications »
Ils sont la manifestation de notre présence en ligne. Des premiers jeux de rôle aux intelligences artificielles qui prennent vie dans les environnements numériques, les avatars ne cessent de voir leurs usages évoluer. Décryptage d’un phénomène intimement lié à nos identités.
Avec « Recherches impliquées », une série d’articles qui fait dialoguer recherche et innovation, onepoint et Usbek & Rica retracent l’histoire des avatars et imaginent leurs évolutions à venir.
Il y a ceux que l’on s’amuse à créer à son image pour interagir avec ses amis sur Facebook, ceux que l’on choisit et personnalise avec attention dans des jeux vidéos immersifs, ou encore ceux dont rêve Mark Zuckerberg pour interagir entre collègues dans le métavers. Comme Vishnou, l’une des principales divinités de l’hindouisme qui a la faculté de prendre différentes apparences, nous interagissons dans les mondes numériques par l’intermédiaire de divers avatars. Le mot vient justement du sanskrit « avatara », désignant les avatars de Vishnou qui « descendent du ciel ».
Années 1970 : « Donjons et Dragons », les prémices des avatars modernes
Ceux qui nous sont devenus si banals dans nos interactions quotidiennes n’ont cependant rien de très ancien ou de divin. Expert en cybersécurité chez onepoint, Vincent Rémon fait remonter la naissance des avatars modernes au célèbre jeu de rôle Donjons et Dragons créé dans les années 1970, qui a permis cette « transposition de soi-même vers un personnage que l’on n’est pas ». Très vite, le monde du jeu vidéo reprend le concept par le biais des MUD (multi-user dungeon), dans lesquels les joueurs incarnent des personnages dans un monde virtuel où ils évoluent et interagissent en tapant des commandes textuelles.
« Ça a été les prémices du MMORPG [jeu de rôle en ligne massivement multijoueur] type World of Warcraft, qui a démocratisé l’avatar auprès du grand public. Cela a nécessité des progrès techniques importants : il a fallu avoir accès à internet avec un débit suffisant, des cartes graphiques 3D, etc. », retrace-t-il. C’est à la même époque que Snow Crash (Le Samouraï virtuel, dans sa traduction française), le roman de science-fiction de Neal Stephenson paru en 1992, popularise le concept d’avatar. Trente ans avant le PDG de Meta, l’auteur y imagine un métavers où les internautes évoluent sous la forme d’avatar pouvant être endommagés par des virus informatiques, infligeant des lésions cérébrales dans la vraie vie.
De nos jours : l’avatar, visage de nos identités numériques
Avec la démocratisation d’Internet, des réseaux sociaux et des jeux vidéos en ligne, les avatars sont désormais partout. Prédéfinis ou personnalisables, imaginés ou fidèles à l’apparence des utilisateurs, ils manifestent notre présence dans les environnements numériques. Leur conception a néanmoins évolué depuis leur percée dans les années 1990. À cette époque, constate la chercheuse Fanny Georges dans un article, « l’avatar incarnait la liberté de se présenter dans l’anonymat nécessaire à l’expérimentation identitaire. Il s’associe aujourd’hui de plus en plus à l’identité numérique (…) L’avatar s’enfouit dans le corps qui reprend sa place de représentation de la personne. Identités ludique, virtuelle et réelle tendent à se mêler. »
Sa définition originelle, créative et ludique, laisse place à une dimension beaucoup plus « conceptuelle », observe de son côté Adahé Saban, doctorant en psychologie du travail et en design au sein de onepoint : « L’avatar désigne avant tout le fait d’interagir avec les autres, et surtout que les autres me reconnaissent. On peut se dire que le curseur de la souris est un avatar parce qu’il permet une interaction avec un environnement numérique, de même qu’une adresse mail. » Loin de l’idée d’évasion portée par le roman de Neal Stephenson, qui donne la « sensation de s’approprier un autre corps, un autre être », l’avatar prend ainsi des formes « désincarnées », poursuit-il.
Demain : des IA parmi nous ?
Cette nouvelle conception de l’avatar, associée aux identités numériques, charrie son lot de (cyber)risques. « Pour que l’avatar soit représentatif de ce que l’on est, il faut que l’on ait confiance dans le fait qu’il ne soit pas usurpé. La garantie d’identité est cruciale », estime Vincent Rémon. À l’ère des deep fakes, permettant de créer des images animées de toutes pièces grâce aux technologies d’intelligence artificielle, « ce n’est pas l’image qui va faire foi, car on ne peut plus lui faire confiance. » Or le recours aux identités dites fédérées, garanties par un organisme central, pose question. « Quand c’est Google ou Facebook qui dit “je sais assez de choses sur un tel pour vous garantir que c’est bien lui qui se connecte”, personnellement ça me fait peur », ajoute l’expert. Ce modèle pourrait être remplacé demain par les identités décentralisées, portées par la blockchain et restant aux mains des utilisateurs à travers l’utilisation d’un portefeuille (wallet) – sorte d’avatar sécurisé – contenant les données personnelles.
Les usages des avatars vont continuer à évoluer. Mais dans quels cadres, et selon quelles règles ? Pourra-t-on être incriminé si notre avatar se rend coupable d’agression sexuelle, par exemple ? Reste aussi à déterminer les usages les plus pertinents dans les environnements numériques de demain. Prenons le monde du travail : « Les avatars professionnels qui nous ressemblent beaucoup, je n’y crois pas trop, car on est déjà tout le temps connectés à la webcam », juge Vincent Rémon. Quant aux avatars non-ressemblants, en revanche, c’est une autre histoire : « Pour des personnes pouvant être discriminées dans le cadre professionnel, c’est aussi une autre manière de se présenter en mettant en avant la compétence plutôt que l’image de soi », fait valoir Adahé Saban.
Dans le futur, la percée des IA pourrait également bousculer nos interactions avec les avatars. Saura-t-on distinguer demain des chatbots perfectionnés munis d’avatars d’un être humain derrière son clavier, et comment adaptera-t-on notre comportement en fonction ? De la même façon, fera-t-on la différence entre le jeu d’acteur de Tom Hanks de son vivant avec celui de l’avatar muni d’une IA qui pourrait lui succéder après sa mort, conformément à son souhait ? Pour Vincent Rémon, la capacité à faire le distingo entre ce qui relève de l’humain ou non sera décisive : « On ira beaucoup plus favorablement vers des outils pour lesquels on a la certitude de savoir si l’entité avec laquelle on interagit est un robot ou non. » On a parfois tendance à l’oublier, mais les relations virtuelles sont avant tout des relations humaines.